The popular name for Convolutional Neural Network (CNN) these days is “Deep Learning” (DL) or Deep Neural Network (DNN). Researchers at Google, Facebook, IBM, Nvidia, and potentially a number of other companies are experimenting with their own variations of DL algorithms based on CNN. Twitter recently acquired a company called Magic Pony to increase focus on DL. Applications for DL range from vision processing for self-driving car applications to natural language processing and face/object recognition, for potential applications in security, advertising, gaming, VR/AR, etc.
A neural network is a computational algorithm that is loosely based on mechanics of the learning process in animals. The name “Convolutional” stems from using the convolution operator during filtering passes of data through the neural network (chart below illustrates the mathematical convolution function). Deployment of neural networks for scientific or commercial applications so far has been largely limited to what’s called “supervised learning” networks. CNN has potential to extend the reach of neural networks into “unsupervised learning” applications.
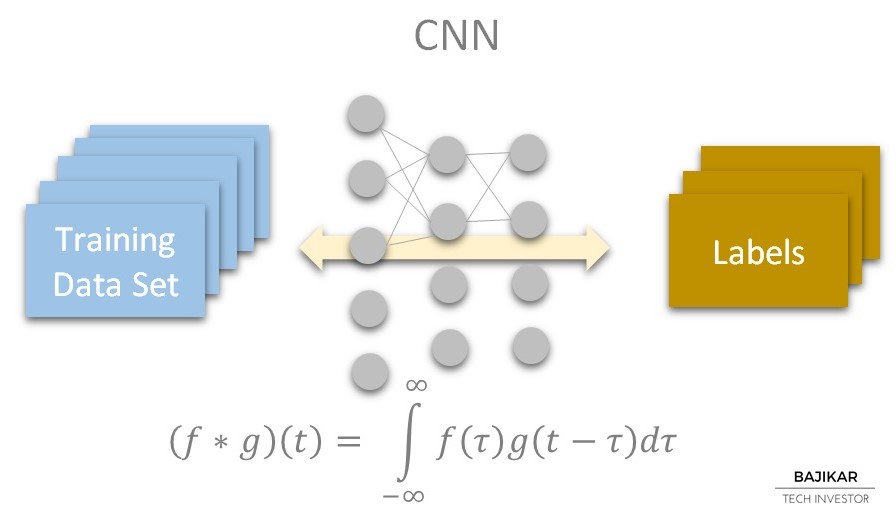
There are two steps to using any neural network:
Step #1 = Train the neural network with a known dataset
Step #2 = Use the trained neural network to “detect” patterns (“Labels” in the chart) in unknown data
Size and parameters of the neural network, size of the training dataset, and computational horsepower available together determine the amount of time required for training.
As an aside, I first used neural networks ~20 years ago, when I developed an algorithm based on a Kohonen Self-Organizing Map for creating a “virtual bumper” using RADAR data to aid in vehicle collision avoidance. The algorithm was programmed in MATLAB, which ran on a SUN or SGI workstation at University of Minnesota. I later implemented the algorithm in a 8-bit VLSI design. Needless to say computing power has come a long way since then, allowing for quicker training of more hidden layers within the neural network.
The power of CNN resides in the “unsupervised” aspect of its training process. Instead of applying predetermined kernel weights (i.e. a predefined digital filter) to extract intelligence from known input data, a CNN configures the filters automatically with emphasis on spatial locality of each input. This means that each CNN is specifically trained for a particular type of operation or dataset, e.g. pedestrian detection while driving, or natural voice recognition, etc.
Given that neural networks in general (CNN included) carry out inherently parallel operations, such algorithms can be accelerated by using parallel computing processors, such as GPUs. Much like Intel’s approach with mass-scale general purpose x86 processors, Nvidia would like the world to use versions of GPUs it sells for computer gaming, extended for CNN applications. If such a general purpose GPU is not good enough, then Google is taking it a step further by building its own TPU (Tensorflow Processor Unit), based on Google’s own Tensorflow architecture for CNN. Apple may have its own such processor up its sleeve, and so may IBM. If you try to think of these developments as applicable within the massive scale of Internet of Things (IoT), including self-driving cars and AR/VR, then initial concerns about cost of development might start to fade – its not like any of these companies is pressed for cash!
References:
IBM Watson-powered Olli Self-Driving Vehicle
nVidia Deep Learning resources for developers
Google Tensorflow
Google TPU chip
Facebook AI Research
Yann LeCun’s website
THIS ARTICLE IS NOT AN EQUITY RESEARCH REPORT.
Disclosure: As of this writing the acteve Model Portfolio did not hold any positions in TWTR, FB, IBM or NVDA, but held long positions in GOOG, INTC, AAPL and MSFT.
Additional Disclosures and Disclaimer

